How to use godom with AI agents
April 29, 2026 • 9 min read
godom ships a docs/llm-reference.md aimed at AI agents writing godom apps. Why that doc exists, what it covers, and what the workflow looks like.
TL;DR
- godom ships a
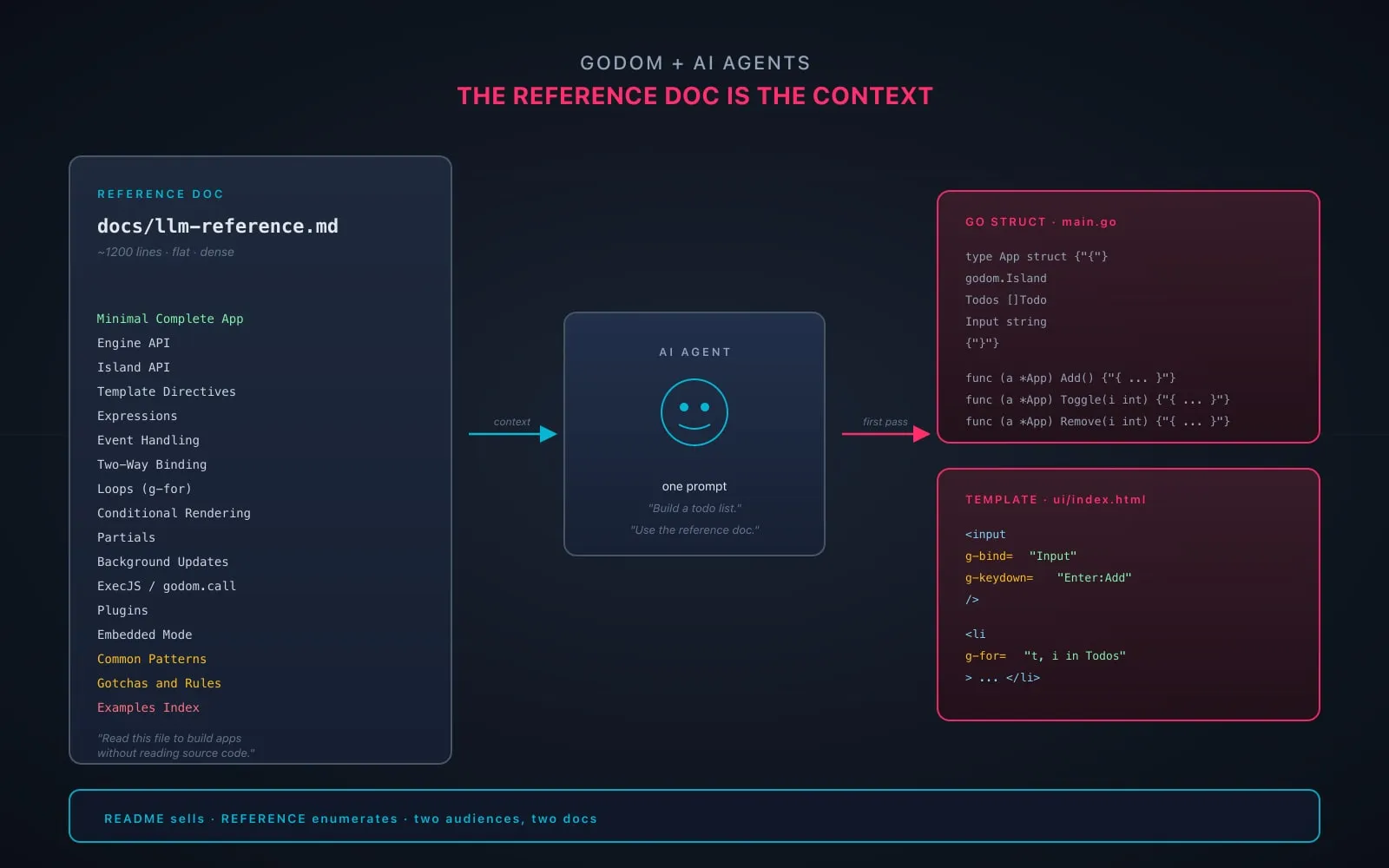
docs/llm-reference.mdaimed at AI agents writing godom apps. It is not the README; it is the API enumerated in the shape an agent needs. - The doc starts with a minimal complete app, then enumerates the engine, the island lifecycle, every directive, the expression grammar, the plugin protocol, common patterns, gotchas, and an examples index. A flat, dense reference, not a tutorial.
- Point an agent at this file and describe an app, and the first draft is usually godom-shaped. Without it, the agent rederives React patterns from training data and the code does not compile.
- This is not magic. The agent still needs steering. The doc lowers the floor; the rest is the same engineering work that any coding agent needs.
The AI-build journal is about how godom itself got built with AI help. This post is the other direction: using AI agents to write apps on top of godom, and the small piece of documentation that makes that workflow viable.
After working with AI coding agents for a while, I’ve handcoded very little Go or HTML myself. The agent writes; I review, redirect, and reject. godom was designed to feel native to that workflow, partly because I am the workflow.
Why a separate doc for agents
The repo has a README.md for humans deciding whether to try godom. It introduces the framework, makes the case, shows a teaser. It is selling.
docs/llm-reference.md is not selling. It is the API laid out in the order an agent needs to consume it. A complete minimal app at the top, then a flat enumeration of every public surface: engine fields and methods, island fields and methods, every g-* directive with examples, the expression grammar, the event handler shape, the partial system, the plugin protocol, the surgical-refresh API, ExecJS, godom.call, drag-and-drop directives, shadow DOM, environment variables, the developer-owned-server pattern, the embedded-mode pattern. Then a section of common patterns, then a gotchas list, then an examples index pointing at every example folder by name and the concepts it demonstrates.
The doc is ~1200 lines. That sounds long for “a reference”; it is short for “the whole framework, enumerated.” There is nothing in it that an agent would have to derive: if an agent reads it before writing godom code, the agent does not need to read the source.
This is calibrated for how coding agents work. They pull what they need into context and produce. If the thing they need is spread across a dozen example folders and a README that sells more than it specifies, the produce step gets shaky. A single tight reference fixes that.
Why the README is not enough
Point an agent at just the README and you get reasonable-looking godom code that does not work. I learned this fast.
I have to admit godom feels a bit different to the agent. The agent has a bias toward how the well-known JS frameworks work; that bias is what shows up first, and it does not fit godom. The first drafts come out shaped like React or Vue, not godom.
A few nudges usually got the code closer, but those nudges were the same nudges every time. Adding a dedicated LLM reference helped more than anything else I tried. The repo’s regular docs have plenty of useful narrative for humans, but that narrative is noise the agent has to filter through; a flat, dedicated reference cuts that out.
A skill would be better still (the way Claude Code skills carry author or project conventions on top of a framework). I believe the skill should be author-specific or project-specific, so a plain reference is the fair thing to ship in the framework itself. You can ask your agent to build the skill for your project: point it at the reference, and even better if it can also go through the code.
The patterns I kept seeing fail:
- Invented directive names. The agent reaches for
g-onclick,g-on:click,g-model,@click,:value. Flavors from Vue, Svelte, Alpine, HTMX, all reasonable guesses from training data. None of them are godom’s. godom usesg-click,g-bind,g-valueand a small fixed list. - Wrong expression grammar. godom expressions take
and,or,notin multi-term boolean expressions, not&&,||,!. String literals need single quotes inside HTML attributes. The agent picks the JS version every time. Refresh()inside an event handler. Double-renders on every click. The framework auto-refreshes after event handlers; manualRefresh()is for goroutines only. (The reference doc lists this as a numbered gotcha. The README only hints at it.)- A JS frontend that didn’t need to exist. Every other Go-template-meets-HTML framework needs one, so the agent reaches for one here. godom does not. The reference doc spells out the constraints that make the JS frontend unnecessary.
Refresh()whereMarkRefresh("Field")would do. Functionally correct, just wasteful: a full re-render when one field changed.
These are training-data artifacts, not reasoning failures. The agent is applying patterns that are correct in the frameworks it was trained on, to a framework it has no training data for. The reference doc closes the gap. It doesn’t make the agent fluent; it gives it the vocabulary on demand, in the file it can pull into context for the duration of the task.
What the doc covers, in the order it covers it
The reference is structured for first-prompt success on a small app, then for picking up complexity from there.
A minimal complete app sits at the top: two files, a Go struct with godom.Island embedded, exported fields, exported methods, a main() that calls eng.QuickServe(app), an HTML template using g-text, g-click, g-bind. That’s the floor. Most apps I ask for are this shape, scaled up.
Then the API, laid flat:
- Engine and Island. Every public field and method, plus the three template-source patterns and the validation rules at
Register(). The agent stops producing configurations thatlog.Fatalon startup. - All
g-*directives in one section. Data display, input binding, conditional rendering, loops, attribute/class/style families, event handlers, the keymap syntax (Enter:Submit), drag-and-drop, scroll, mousemove, wheel. No hunting through example folders. - Two-way binding semantics. Every keystroke crosses the wire; no debounce; that’s why both tabs stay in sync.
- Background updates.
Refresh()from a goroutine vs.MarkRefresh(...)for surgical patches. The distinction matters; the doc spells it out. - ExecJS and
godom.call. The two doors through the bridge. Code examples for both directions, exactly how I’d want them shown if I forgot the API. - Plugins.
eng.RegisterPlugin("name", scripts...), the adapter shape (init/update), theg-plugin:name="Field"template syntax. Both the local-adapter and reusable-package flavors. - Embedded mode.
NoBrowser,GODOM_WS_URL, host-page integration, shadow DOM. The case the composition post sketched. - Patterns and gotchas. “Do not call Refresh inside event handlers.” “Do not reset IDCounter.” “Events are serialized per island.” “Use
and/or/not.” “Single quotes inside HTML attribute strings.” Each is one numbered line. No prose. - Examples index. A table mapping example folder name to the concepts it demonstrates. When I need a working analogue of “Chart.js plugin + live data,” the index points the agent at
system-monitor-chartjs. That folder becomes the next layer of context.
Almost no narrative. Narrative is for humans; agents pay for it in tokens.
What a working prompt looks like
The prompt that gets useful godom code on the first try has three parts.
- Pull in the reference. “Read
docs/llm-reference.mdfirst. Use only directives, expressions, and APIs from that file.” This anchors the agent to godom’s vocabulary instead of an inherited one. - State the app in terms of state and behavior. “A todo list. Items are strings. Add via an input plus Enter. Toggle done with a checkbox. Remove with a button. Persist nothing.” The agent now has the Go struct (a slice of structs, a method per behavior) and the template (an input with
g-bindandg-keydown, ag-forover the slice, two methods bound tog-click). - Reference an example for shape. “Pattern after
examples/todolist/.” If the example does the thing you want, point at it. The agent reads it, internalizes the shape, and produces something consistent with the rest of the repo.
That prompt usually produces compilable, idiomatic godom code in one pass. Not because the agent is fluent in godom; because the constraints are tight enough that there is only one shape that fits.
For larger work, add a fourth part: a thesis. “Don’t introduce any plain JavaScript. Don’t use a router. The app is single-page.” Constraints up front are cheaper than reverts later. The JS surface post is the long-form version of one such constraint.
If you’d rather write the code yourself instead of prompting an agent, the how-to-use-godom walkthrough builds the same kind of small app in three stages, by hand.
Where agents still trip up
The reference doc lowers the floor. It does not raise the ceiling. Several failure modes survive it, and I steer past them on most sessions.
- Bridge logic. The thin-bridge post has the long version. Agents are biased toward making the browser smarter. Even with the reference in hand, the agent will sometimes propose a JS-side cache, a JS-side validation, or a JS-side state mirror. The fix is always the same: “we don’t do that here; the Go side already does it.” The reference doc warns; the agent occasionally forgets.
- Plugin scope creep. Ask the agent to integrate a JS library and it’ll sometimes propose plugins that have their own configuration system on the JS side, or that interpret Go data before drawing. The plugin’s brief is two functions:
initandupdate. Anything more is the framework re-emerging in JS. - Speculative architecture. Ask for a small dashboard and the agent sometimes hands back a “metrics service” with interfaces, factories, and an injection layer. godom apps are usually one file. The reference doc emphasizes simplicity but does not fight ceremony directly; that part is steering work.
- Hallucinated imports. Now and then the agent will import a package that doesn’t exist (a fictional
godom/dom, say) because the API surface looks like one. The reference doc lists the actual imports, but a hurried agent will guess. It catches itself ongo mod tidy.
These are not godom problems. They are coding-agent problems with a godom flavor. The reference doc handles the godom flavor. The general AI-coding problems are the general AI-coding problems, and they need the same steering they always did.
The honest framing
docs/llm-reference.md is not a magic ticket. The framework is small enough that a careful human can write the same code without it. What the doc buys is consistency and speed: a coding agent can land a first draft of a small godom app in minutes, and that draft will compile and run and look like the rest of the repo.
It buys that consistency by being boring on purpose. No marketing copy. No “why godom is different.” Just APIs, directives, expressions, gotchas, examples. The README sells; the reference enumerates. Two audiences, two docs.
The pattern transfers. If you build any framework you’d like AI agents to use, a flat, enumerated reference next to the README is cheap to write and pays back immediately. The agent is not going to invent your conventions correctly. Giving it the conventions in a file it can read is the smallest possible thing that turns a hallucinating tool into a useful one.